
一般社団法人データサイエンティスト協会様より表題『データサイエンス100本ノック』には以前より興味があったので、できるだけ丁寧にやってみようと思います。
公式はコチラ
https://github.com/The-Japan-DataScientist-Society/100knocks-preprocess
![]()
![]()
- 環境構築についてはコチラを参照
- 【1】データフレームの先頭行を表示する
- 【2】データフレームの任意のカラムを10件表示
- 【3】カラムの名称を変更して表示
- 【4】指定の条件に合致した行だけ表示する
- 【5】指定の条件に合致した行だけ表示(複合)
- 【6】指定の条件に合致した行だけ表示(複合)
- 【7】指定の条件に合致した行だけ表示(複合)範囲条件
- 【8】指定の条件に合致した行だけ表示(複合)指定以外を抽出
- 【9】notを付けたカッコの外し方
- 【10】文字列の始まりが S14◯◯◯◯ となっているものの抽出
- 【11】文字列の末尾 1 となっている行を抽出
- 【12】文字列の『横浜市』を含む行を抽出
- 【13】正規表現に合致する行を抽出する
- 【14】正規表現に合致する行を抽出する
- 【15】正規表現に合致する行を抽出する(複合)
- 【16】正規表現に合致する行を抽出する(複合)桁数の抽出
- 【17】ソートして表示する。昇順
- 【18】ソートして表示する。降順
- 【19】ランクを付与して表示する(ランクの重複があり)
- 【20】ランクを付与して表示する(ランクの重複なし)
- 【21】行列の個数をカウントする
- 【22】ユニークな要素のカウント
- 【23】グルーピングし統計量算出する
- 【24】グルーピングし、新しい順に並べる
- 【25】グルーピングし、古い順に並べる
- 【26】並べ替えたデータフレームを格納し、joinメソッドでカラム名をcolumnsパラメータを並べ替えし、qurryメソッドで並べ替える
- 【27】属性ごとの平均値を出し、降順に並べ替える
- 【28】属性ごとの中央値を出し、降順に並べ替える
- 【29】属性ごとのアイテムの最頻値を抽出して並べる
- 【30】属性ごとのアイテムの標本分散を抽出して並べる
- 【31】属性ごとのアイテムの標本標準偏差を抽出して並べる
- 【32】属性の25刻みのパーセンタイル値を出す
- 【33】属性ごとのアイテムの平均を出し、◯◯以上を抽出
- 【34】属性ごとの合計を出して、その平均値を出す。ただし、除外する条件あり
- 【35】属性ごとの合計値の平均を出し、その値以上となるアイテムを抽出する
- 【36】データフレームを内部結合し、必要な列を表示
- 【37】データフレームを内部結合し、必要な列を表示
- 【38】結合して合計、nullの処理と、特定項目は除外する
- 【39】DFをそれぞれ更新して、外部結合する
- 【40】直積したデータ件数をカウントする
- 【41】日付ごとの売上金額を合計し、前日からの増分を計算する
- 【42】各日付のamountデータを1,2,3日前のデータと結合する
- 【43】dfを結合した上で、年代と性別ごとのクロス集計をする
- 【44】43の並びを変更して縦持ちにする
- 【45】日付データをYYYYMMDDに変換する
- 【47】YYYYMMDD形式を日付型に変換し結合
- 【48】UNIX秒を日付型に変換する
- 【49】エポック秒を日付型に変換し年度のみ抽出する
- 【50】エポック秒を日付型に変換し、月度を抽出する。ただし、月は0埋めの2桁表示で抽出する
環境構築についてはコチラを参照
分かる人なら公式記載の導入手順でなんとかなるのかもしれませんが、結構手こずりました・・・。
Windows10HomeEditionの方はコチラ

Windows10Proの方はコチラ

【1】データフレームの先頭行を表示する
これは簡単headメソッドですね。
headメソッドの復習

回答
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].head(10)【2】データフレームの任意のカラムを10件表示
任意のカラムの表示方法の復習


で【1】のheadを組み合わせる
回答
df_receipt[['sales_ymd','customer_id','product_cd','amount']].head(10)【3】カラムの名称を変更して表示
renameメソッドを使用する
renameメソッドの復習

回答
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].rename(columns={'sales_ymd': 'sales_date'}).head(10)【4】指定の条件に合致した行だけ表示する
queryメソッドを使用する
queryメソッドの復習
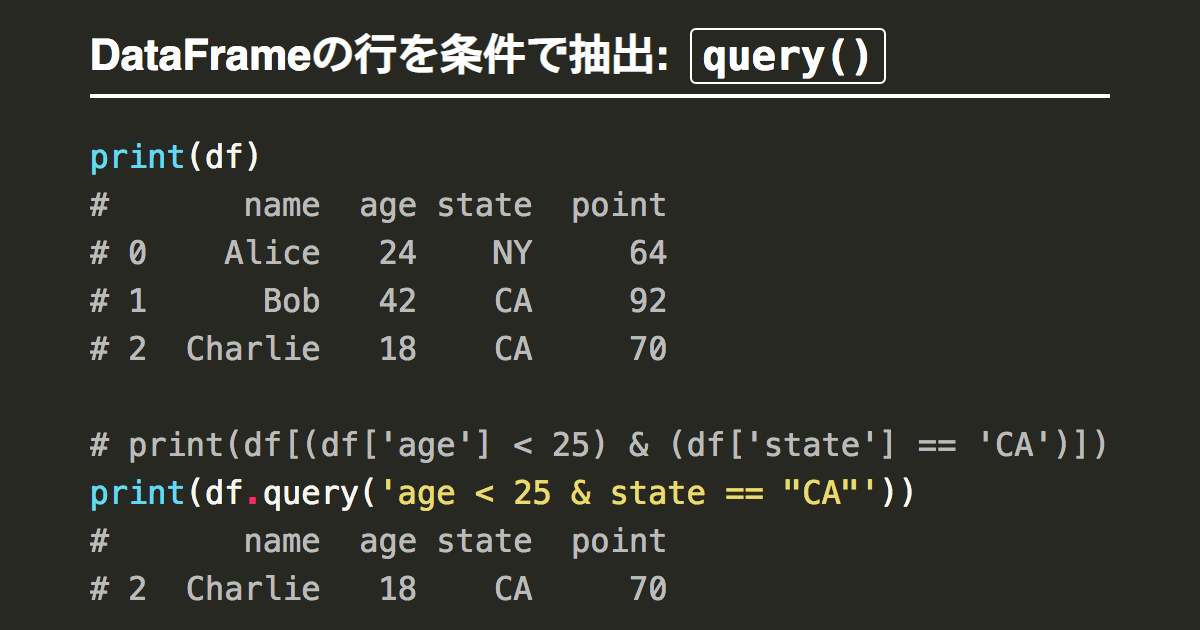
回答
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].query('customer_id == "CS018205000001"')【5】指定の条件に合致した行だけ表示(複合)
注意点:pythonのandは【&】だけで良い。(&&ではない)
回答
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']]\
.query('customer_id == "CS018205000001" & amount >= 1000')※ jupyter Lab のセル内で改行するときは【\】をつける
【6】指定の条件に合致した行だけ表示(複合)
注意点:andとorの優先順位→明示的に()を使用する
回答
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'quantity', 'amount']].query('customer_id == "CS018205000001" & (amount >= 1000 | quantity >=5)')【7】指定の条件に合致した行だけ表示(複合)範囲条件
注意点:範囲指定のときは 10 <= amount <= 20 という書き方ができる
回答
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']] \
.query('customer_id == "CS018205000001" & 1000 <= amount <= 2000')【8】指定の条件に合致した行だけ表示(複合)指定以外を抽出
注意点:「以外」は != を使う
回答
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].query('customer_id == "CS018205000001" & product_cd != "P071401019"')【9】notを付けたカッコの外し方
not演算子の復習


回答
df_store.query('prefecture_cd != "13" & floor_area <= 900')【10】文字列の始まりが S14◯◯◯◯ となっているものの抽出
復習:startswithメソッドを使用する
回答
df_store.query("store_cd.str.startswith('S14')", engine='python').head(10)【11】文字列の末尾 1 となっている行を抽出
復習:endsWithメソッドの使用

回答
df_customer.query("customer_id.str.endswith('1')", engine='python').head(10)【12】文字列の『横浜市』を含む行を抽出
復習:str.contains()メソッド
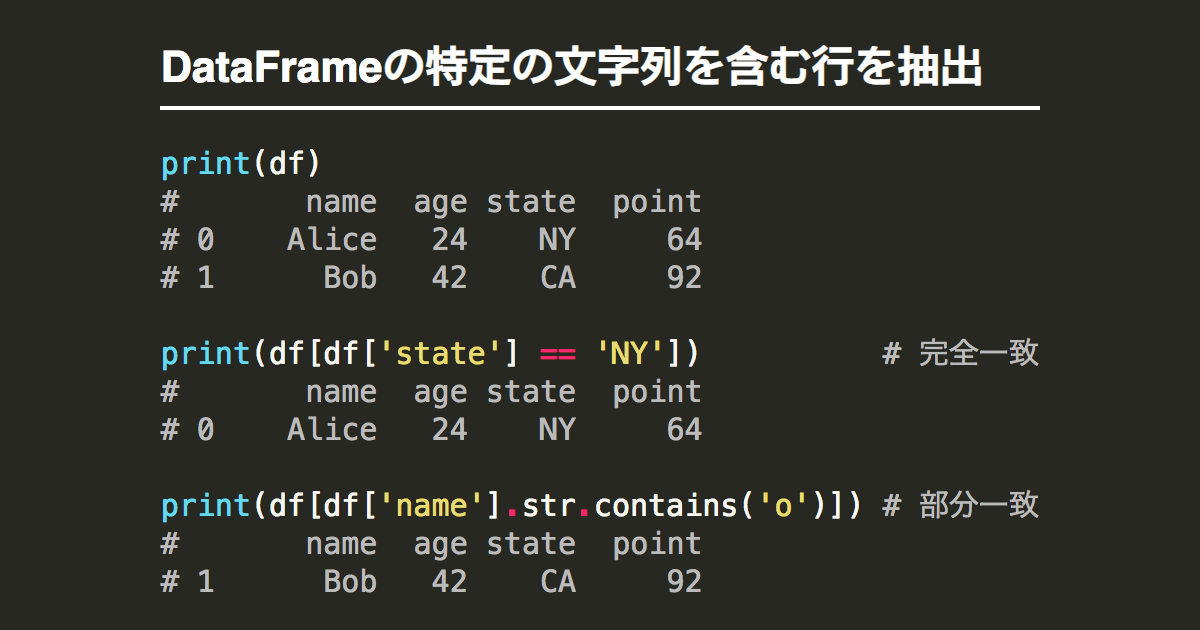
回答
df_store.query("address.str.contains('横浜市')", engine='python').head(10)【13】正規表現に合致する行を抽出する
復習:正規表現

回答
df_customer.query("status_cd.str.contains('^[A-F]', regex=True)", engine='python').head(10)【14】正規表現に合致する行を抽出する
回答
df_customer.query("status_cd.str.contains('[1-9]$', regex=True)", engine='python').head(10)【15】正規表現に合致する行を抽出する(複合)
回答
df_customer.query("status_cd.str.startswith('^[A-F]', regex=True)", engine='python').head(10)【16】正規表現に合致する行を抽出する(複合)桁数の抽出
回答
df_store.query("tel_no.str.contains('^[0-9]{3}-[0-9]{3}-[0-9]{4}$', regex=True)", engine='python')【17】ソートして表示する。昇順
復習:pythonのソート
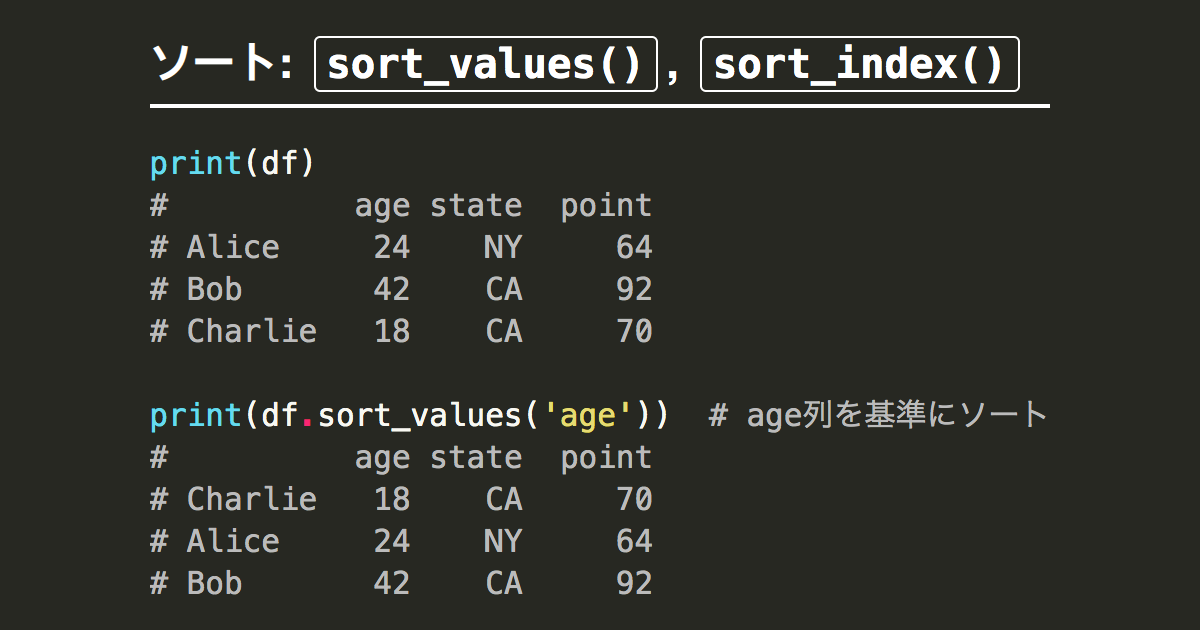


回答
df_customer.sort_values('birth_day', ascending=True).head(10)【18】ソートして表示する。降順
回答
df_customer.sort_values('birth_day', ascending=False).head(10)【19】ランクを付与して表示する(ランクの重複があり)
復習:rankメソッド

復習:concatメソッド

回答
df_tmp = pd.concat([df_receipt[['customer_id', 'amount']]
,df_receipt['amount'].rank(method='min', ascending=False)], axis=1)
df_tmp.columns = ['customer_id', 'amount', 'ranking']
df_tmp.sort_values('ranking', ascending=True).head(10)【20】ランクを付与して表示する(ランクの重複なし)
回答
df_tmp = pd.concat([df_receipt[['customer_id', 'amount']]
,df_receipt['amount'].rank(method='first', ascending=False)], axis=1)
df_tmp.columns = ['customer_id', 'amount', 'ranking']
df_tmp.sort_values('ranking', ascending=True).head(10)【21】行列の個数をカウントする
これは len関数 ですね
復習:len関数
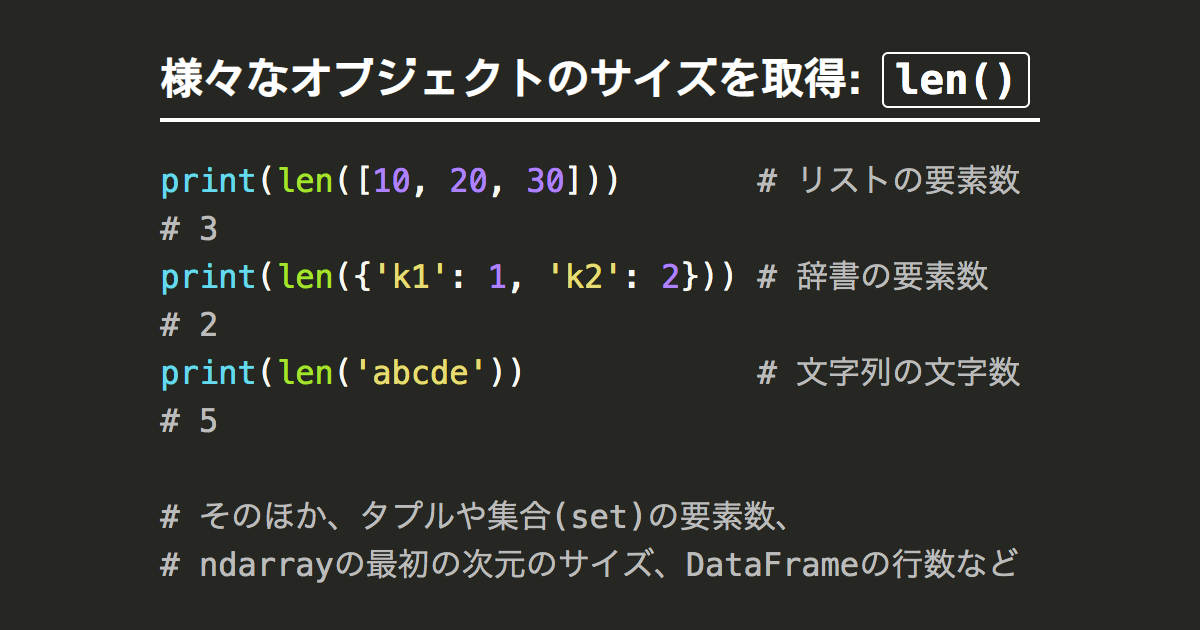
回答
len(df_receipt)【22】ユニークな要素のカウント
uniqueメソッドを使用する
復習:unique()メソッド
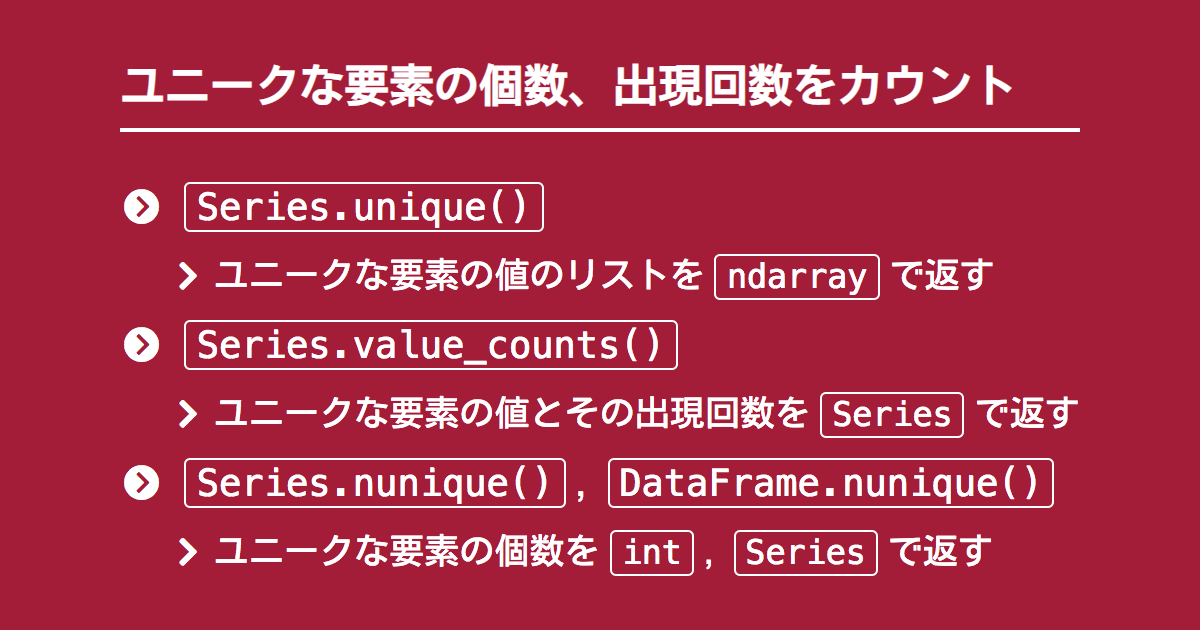
注意点:カウントもするので、len関数との複合です
len(df_receipt['customer_id'].unique())【23】グルーピングし統計量算出する
復習:groupbyメソッド
df_receipt.groupby('store_cd').agg({'amount':'sum', 'quantity':'sum'}).reset_index()注意点:reset_index()メソッドを足すことで、行のインデックスの振り直しをした方が、今後の取り回しがしやすい
【24】グルーピングし、新しい順に並べる
年月の新しいは max メソッドで抽出する
復習:maxメソッド

回答
df_receipt.groupby('customer_id').sales_ymd.max().reset_index().head(10)【25】グルーピングし、古い順に並べる
基本的には24と同じ
回答
df_receipt.groupby('customer_id').sales_ymd.min().reset_index().head(10)
# これでも良い
# df_receipt.groupby('customer_id').agg({'sales_ymd':'min'}).head(10)※aggメソッドイズ何?

【26】並べ替えたデータフレームを格納し、joinメソッドでカラム名をcolumnsパラメータを並べ替えし、qurryメソッドで並べ替える
復習:joinメソッド

復習:columnsインスタンス

復習:queryメソッド
回答
df_tmp = df_receipt.groupby('customer_id').agg({'sales_ymd':['max','min']}).reset_index()
df_tmp.columns = ["_".join(pair) for pair in df_tmp.columns]
df_tmp.query('sales_ymd_max != sales_ymd_min').head(10)【27】属性ごとの平均値を出し、降順に並べ替える
復習:sort_valuesメソッド
回答
df_receipt.groupby('store_cd').agg({'amount':'median'}).reset_index().sort_values('amount', ascending=False).head(5)【28】属性ごとの中央値を出し、降順に並べ替える
基本的に27と同じ
回答
df_receipt.groupby('store_cd').agg({'amount':'median'}).reset_index().sort_values('amount', ascending=False).head(5)【29】属性ごとのアイテムの最頻値を抽出して並べる
復習:applyメソッド

回答
df_receipt.groupby('store_cd').product_cd.apply(lambda x: x.mode()).reset_index()【30】属性ごとのアイテムの標本分散を抽出して並べる
ddofとは?
(省略可能)初期値0
標準偏差を計算する際にデータの個数で割り算を行う際、本来のデータの個数Nではなく”N-ddof”で割るようにします。これによってデータの自由度が増加します。
復習:np.var関数

回答
df_receipt.groupby('store_cd').amount.var(ddof=0).reset_index().sort_values('amount', ascending=False).head(5)【31】属性ごとのアイテムの標本標準偏差を抽出して並べる
TIPS:
PandasとNumpyでddofのデフォルト値が異なることに注意しましょう
Pandas:
DataFrame.std(self, axis=None, skipna=None, level=None, ddof=1, numeric_only=None, **kwargs)
Numpy:
numpy.std(a, axis=None, dtype=None, out=None, ddof=0, keepdims=)
回答
df_receipt.groupby('store_cd').amount.std(ddof=0).reset_index().sort_values('amount', ascending=False).head(5)【32】属性の25刻みのパーセンタイル値を出す
復習:np.percentile
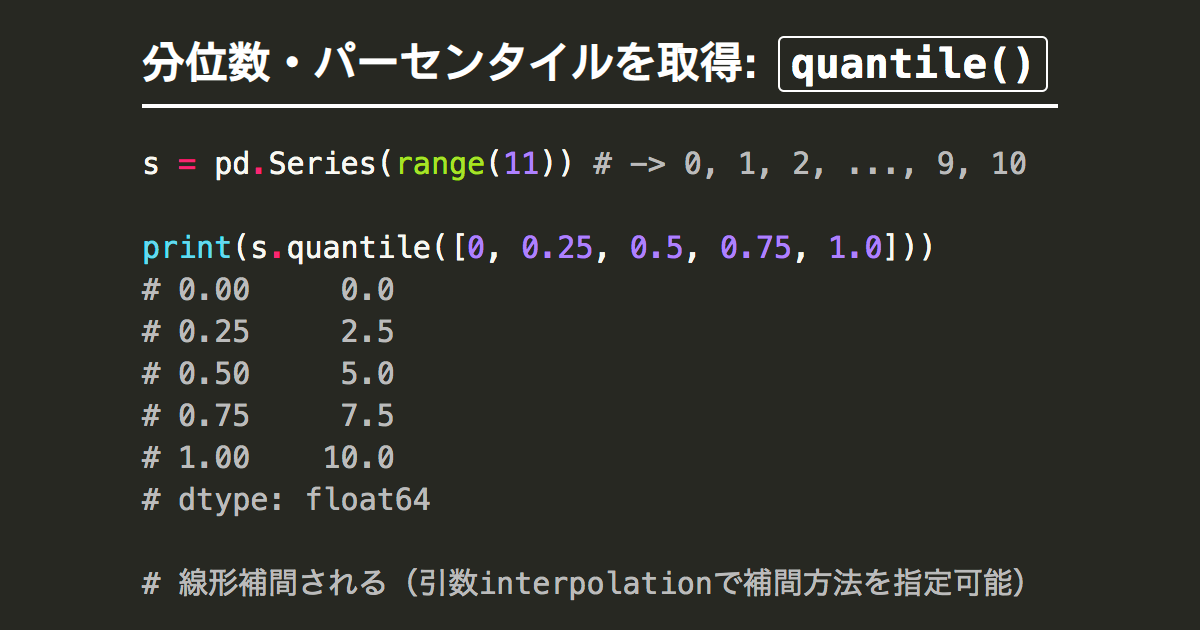
回答1
np.percentile(df_receipt['amount'], q=[25, 50, 75,100])復習:quantile
回答2
df_receipt.amount.quantile(q=np.arange(5)/4)【33】属性ごとのアイテムの平均を出し、◯◯以上を抽出
いままでの複合
回答
df_receipt.groupby('store_cd').amount.mean().reset_index().query('amount >= 330')【34】属性ごとの合計を出して、その平均値を出す。ただし、除外する条件あり
queryを使わない書き方
復習:startswith()
回答1
df_receipt[~df_receipt['customer_id'].str.startswith("Z")].groupby('customer_id').amount.sum().mean()queryを使う場合
回答2
df_receipt.query('not customer_id.str.startswith("Z")', engine='python').groupby('customer_id').amount.sum().mean()【35】属性ごとの合計値の平均を出し、その値以上となるアイテムを抽出する
①平均値を変数に格納する
②データフレームに属性ごとの合計値を格納する
③②のデータフレームの中の①以上となっている値を抽出する
回答
amount_mean = df_receipt[~df_receipt['customer_id'].str.startswith("Z")].groupby('customer_id').amount.sum().mean()
df_amount_sum = df_receipt.groupby('customer_id').amount.sum().reset_index()
df_amount_sum[df_amount_sum['amount'] >= amount_mean].head(10)【36】データフレームを内部結合し、必要な列を表示
復習:内部結合
回答
pd.merge(df_receipt, df_store[['store_cd','store_name']], how='inner', on='store_cd').head(10)【37】データフレームを内部結合し、必要な列を表示
論点は【36】と同じ
復習:内部結合
回答
pd.merge(df_product
, df_category[['category_small_cd', 'category_small_name']]
, how='inner', on='category_small_cd').head(10)【38】結合して合計、nullの処理と、特定項目は除外する
手順
①属性ごとの合計値を出す→DF1
②排他条件を指定したDFを作る→DF2
③DF1とDF2を左結合する
回答
df_amount_sum = df_receipt.groupby('customer_id').amount.sum().reset_index()
df_tmp = df_customer.query('gender_cd == "1" and not customer_id.str.startswith("Z")', engine='python')
pd.merge(df_tmp['customer_id'], df_amount_sum, how='left', on='customer_id').fillna(0).head(10)【39】DFをそれぞれ更新して、外部結合する
回答
df_sum = df_receipt.groupby('customer_id').amount.sum().reset_index()
df_sum = df_sum.query('not customer_id.str.startswith("Z")', engine='python')
df_sum = df_sum.sort_values('amount', ascending=False).head(20)
df_cnt = df_receipt[~df_receipt.duplicated(subset=['customer_id', 'sales_ymd'])]
df_cnt = df_cnt.query('not customer_id.str.startswith("Z")', engine='python')
df_cnt = df_cnt.groupby('customer_id').sales_ymd.count().reset_index()
df_cnt = df_cnt.sort_values('sales_ymd', ascending=False).head(20)
pd.merge(df_sum, df_cnt, how='outer', on='customer_id')【40】直積したデータ件数をカウントする
回答
df_store_tmp = df_store.copy()
df_product_tmp = df_product.copy()
df_store_tmp['key'] = 0
df_product_tmp['key'] = 0
len(pd.merge(df_store_tmp, df_product_tmp, how='outer', on='key'))【41】日付ごとの売上金額を合計し、前日からの増分を計算する
手順)
df_receiptからsales_ymdとamountの列を抜き出す
それをsales_ymdでグループにして合計する
(行のインデックスが外れるのでreset_index()する)
→新規dfに代入
新規dfを一行ずらしたdf2を作成する→shift()
新規dfにdf2を横方向に結合する→pd.concat([ , ], axis=1)
→新規dfに再代入
一行ずらしたdfの列名を付け直す→.columns = [”,”,”]
差分を表示する新規列を追加する
参照)
shift
https://note.nkmk.me/python-pandas-shift/
concat
columns
回答
df_sales_amount_by_date = df_receipt[['sales_ymd', 'amount']].groupby('sales_ymd').sum().reset_index()
df_sales_amount_by_date = pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift()], axis=1)
df_sales_amount_by_date.columns = ['sales_ymd','amount','lag_ymd','lag_amount']
df_sales_amount_by_date['diff_amount'] = df_sales_amount_by_date['amount'] - df_sales_amount_by_date['lag_amount']
df_sales_amount_by_date.head(10)【42】各日付のamountデータを1,2,3日前のデータと結合する
手順)
【41】同様に日付とamountの合計データを作成する
繰り返しのfor in 文でそれぞれ1,2,3日前のずらしたデータを作成し、横または縦方向に結合する
※1回目のデータは横結合、2、3回目は縦結合
列名をつけなおす
sales_ymdで昇順ソートする
回答
df_sales_amount_by_date = df_receipt[['sales_ymd', 'amount']].groupby('sales_ymd').sum().reset_index()
for i in range(1, 4):
if i == 1:
df_lag = pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift(i)],axis=1)
else:
df_lag = df_lag.append(pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift(i)],axis=1))
df_lag.columns = ['sales_ymd', 'amount', 'lag_ymd', 'lag_amount']
df_lag.dropna().sort_values(['sales_ymd','lag_ymd']).head(10)【43】dfを結合した上で、年代と性別ごとのクロス集計をする
パターン1の手順)
レシートdfに顧客dfを内部結合する
年齢の列を一桁下げてから、小数点以下を切り捨てて、10を掛け戻し、年代ごとに変換し、新しい列に追加する
.pivot_tableを使ってピボットテーブルを作成する
必要な行のみ抽出する
apply関数:pandasで要素、行、列に関数を適用するmap, applymap, apply
math.floor():小数点以下の切り捨て

.pivot_table:pandasのピボットテーブルでカテゴリ毎の統計量などを算出
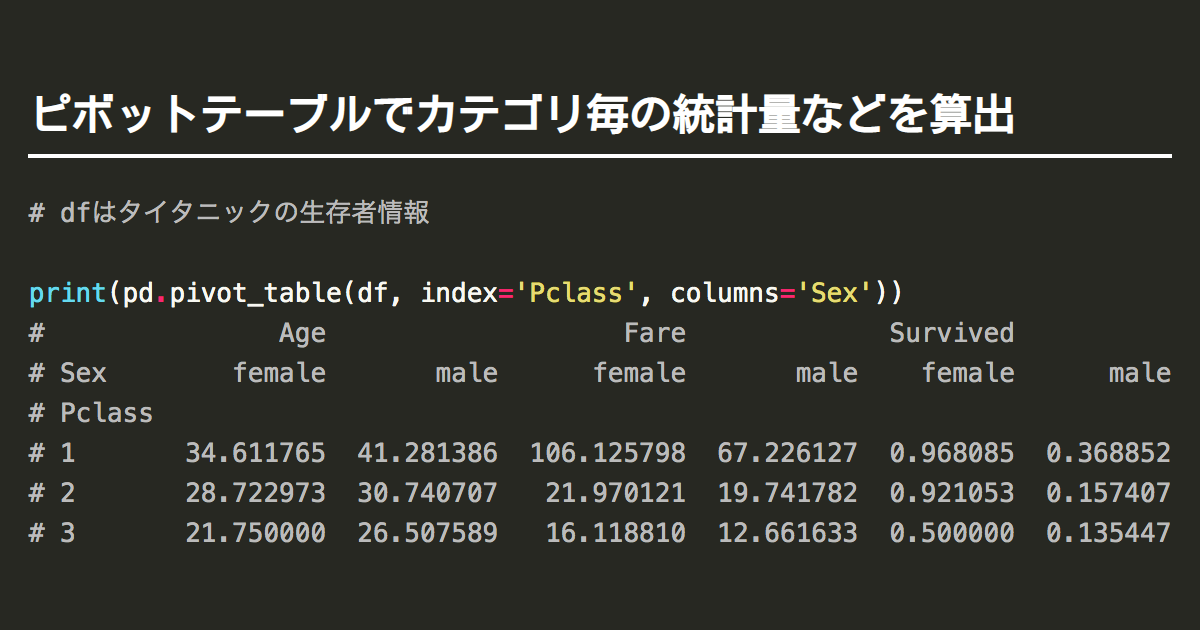
回答
df_tmp = pd.merge(df_receipt, df_customer, how ='inner', on="customer_id")
df_tmp['era'] = df_tmp['age'].apply(lambda x: math.floor(x / 10) * 10)
df_sales_summary = pd.pivot_table(df_tmp, index='era', columns='gender_cd', values='amount', aggfunc='sum').reset_index()
df_sales_summary.columns = ['era', 'male', 'female', 'unknown']
df_sales_summary【44】43の並びを変更して縦持ちにする
stack():pandasでstack, unstack, pivotを使ってデータを整形
回答
df_sales_summary = df_sales_summary.set_index('era'). \
stack().reset_index().replace({'female':'01',
'male':'00',
'unknown':'99'}).rename(columns={'level_1':'gender_cd', 0: 'amount'})
df_sales_summary【45】日付データをYYYYMMDDに変換する
dt.strftime:pandasで日付・時間の列を処理(文字列変換、年月日抽出など)
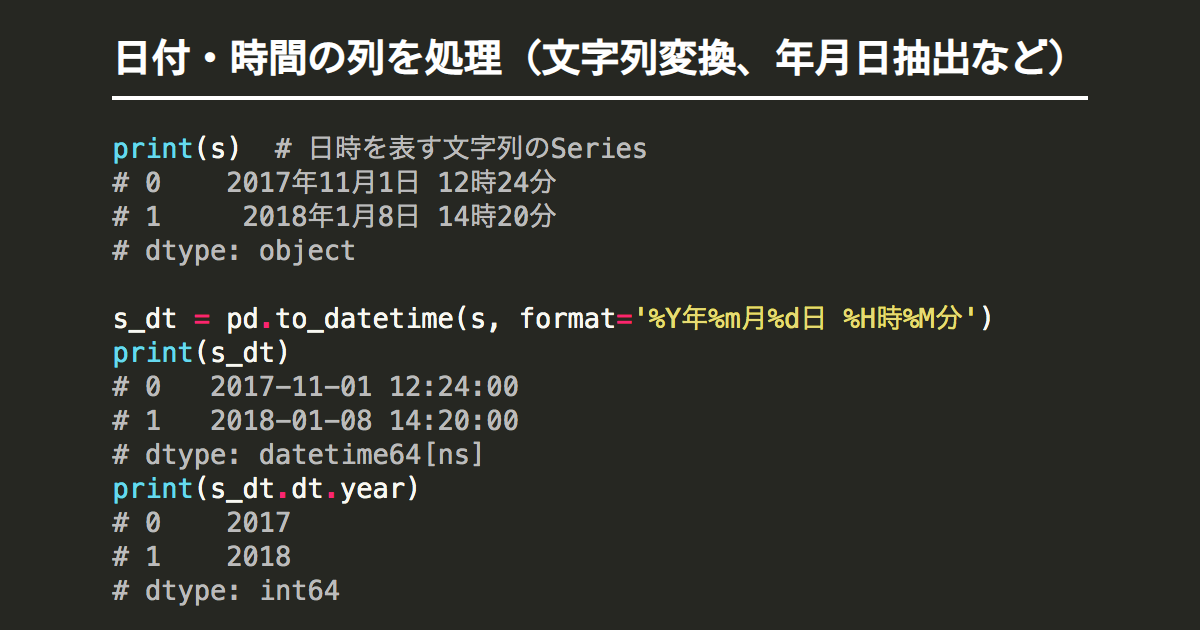
回答
pd.concat([df_customer['customer_id'],
pd.to_datetime(df_customer['birth_day']).dt.strftime('%Y%m%d')],
axis = 1).head(10)【46】YYYYMMDD形式を日付データに変換する
to_datetime:pandasで日付・時間の列を処理(文字列変換、年月日抽出など)
回答
pd.concat([df_customer['customer_id'],pd.to_datetime(df_customer['application_date'])], axis=1).head(10)【47】YYYYMMDD形式を日付型に変換し結合
.astype:NumPyのデータ型dtype一覧とastypeによる変換(キャスト)

回答
pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']],
pd.to_datetime(df_receipt['sales_ymd'].astype('str'))],axis=1).head(10)【48】UNIX秒を日付型に変換する
回答
pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']],
pd.to_datetime(df_receipt['sales_epoch'], unit='s')],axis=1).head(10)【49】エポック秒を日付型に変換し年度のみ抽出する
dt.year:Pandas の日時列から月と年を別々に抽出する方法

回答
pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']],
pd.to_datetime(df_receipt['sales_epoch'], unit='s').dt.year],axis=1).head(10)【50】エポック秒を日付型に変換し、月度を抽出する。ただし、月は0埋めの2桁表示で抽出する
回答
# dt.monthでも月を取得できるが、ここでは0埋め2桁で取り出すためstrftimeを利用している
pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']],
pd.to_datetime(df_receipt['sales_epoch'], unit='s').dt.strftime('%m')],axis=1).head(10)
 |
 |
|---|


コメント